Spark源码学习之IDEA源码阅读环境搭建
Apache Spark作为当今最流行的大数据处理框架之一,其源码学习对于深入理解分布式计算原理和性能优化至关重要。本文将详细介绍如何在IntelliJ IDEA中搭建Spark源码阅读环境,帮助开发者高效地浏览和调试Spark核心代码。
一、环境准备
在开始之前,请确保系统已安装以下工具:
- Java 8或11(Spark 3.x支持Java 11)
- Scala 2.12(与Spark版本匹配)
- Git
- IntelliJ IDEA(社区版或旗舰版)
- Maven 3.6+
二、下载Spark源码
1. 访问Spark官方GitHub仓库(https://github.com/apache/spark)。
2. 使用Git克隆源码到本地:
`bash
git clone https://github.com/apache/spark.git
cd spark
`
3. 切换至特定版本分支(可选),例如:
`bash
git checkout v3.3.0
`
三、配置IDEA项目
- 打开IntelliJ IDEA,选择“Open”并导入Spark根目录。
- 等待IDEA自动检测项目类型(Maven项目),并加载依赖。
- 启用Scala插件:在“File” > “Settings” > “Plugins”中搜索并安装Scala插件(若未安装)。
- 配置SDK:在“File” > “Project Structure”中设置JDK和Scala SDK,确保版本与Spark要求一致。
四、解决依赖与编译问题
1. 使用Maven生成IDEA模块文件:
`bash
./build/mvn idea:idea -DskipTests
`
- 在IDEA中刷新Maven项目:点击右侧Maven面板的“Reload All Maven Projects”。
- 处理可能的依赖冲突:通过Maven排除冲突包,或使用
-Dscala.version参数指定Scala版本。
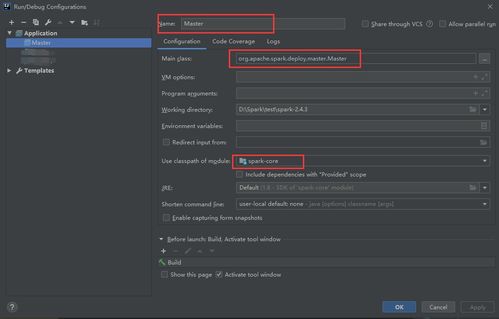
五、调试与测试
- 运行示例代码:打开
examples模块中的类(如SparkPi),右键选择“Run”或“Debug”。 - 设置断点:在核心类(如
SparkContext)中设置断点,通过调试模式观察执行流程。 - 运行单元测试:在
src/test目录下选择测试类,验证环境是否正常。
六、常见问题与技巧
- 内存不足:在IDEA的
vmoptions中增加堆内存(如-Xmx4G)。 - Scala版本兼容性:确保IDEA的Scala编译器版本与项目一致。
- 加速编译:使用
-DskipTests跳过测试,或仅编译特定模块。
通过以上步骤,您已成功搭建Spark源码阅读环境。可以结合官方文档和代码注释,深入分析Spark的调度、存储、SQL等模块实现原理。持续实践与调试,将显著提升对分布式系统的理解能力。
如若转载,请注明出处:http://www.w-share.com/product/255.html
更新时间:2025-11-29 10:25:00